Figure
1.
Simulated bathymetric distribution of the studied area.
| Citation: | Yahui Liu, Hengxiao Li, Jichao Wang. A deep learning model for ocean surface latent heat flux based on Transformer and data assimilation[J]. Acta Oceanologica Sinica. doi: 10.1007/s13131-024-2392-x

|
Ocean surface latent heat fluxes are essential to the energy transfer between the ocean and the atmosphere (Liu et al., 2024). Accurate prediction of these fluxes is crucial to understanding climate change, improving weather forecasts, and protecting marine ecosystems (Bonan and Doney, 2018). Advances in satellite remote sensing technology have enabled us to observe the global ocean at high spatial resolution and in continuous time series, providing a wide range of coverage (Pettorelli et al., 2018). This technology allows us to acquire high spatial and temporal resolution data, such as ocean surface latent heat fluxes and sea surface height anomalies. Using these data, scientists simulate thermodynamic and kinetic processes in the ocean through a series of physically constrained equations. Despite relying on numerical dynamics and physical model simulation techniques, these methods encounter substantial challenges in practical applications due to their computational intensity and sensitivity to variations in the ocean environment (Krasnopolsky and Chevallier, 2003).
Deep learning (DL) excels in spatio-temporal prediction by efficiently managing large datasets and revealing complex relationships in historical data. Recurrent Neural Networks (RNN) and their extensions (Muhuri et al., 2020), such as Long Short-Term Memory (LSTM) networks (Hochreiter and Schmidhuber, 1997), have been shown to be effective in detecting temporal patterns in time-series data. Augmenting the LSTM model with convolutional layers to form a Convolutional LSTM (ConvLSTM) network can further handle spatial correlations, thus improving spatio-temporal prediction. However, RNN and LSTM models have limitations in dealing with long-range dependencies. The introduction of the Transformer model provides a new solution. Unlike RNN and LSTM models, Transformer model does not rely on sequence order to process data but simultaneously focuses on all positions in the sequence through a self-attention mechanism (Chen et al., 2024), making it more efficient in processing data with long time spans (Han et al., 2021). Additionally, the encoder-decoder structure in the Transformer model enables it to flexibly process various types of input and output data, further enhancing its adaptability and application scope.
The application of DL to the mathematical modeling of dynamic systems has attracted much attention in recent years (Erturk and Inman, 2008). Many studies have focused on enhancing the data assimilation (DA) process and improving the accuracy of system predictions through DL techniques. Notably, Yang et al. (Yang and Grooms, 2021) highlighted the ability of generative models to generate ensembles in DA driven by simulation (Maulik et al., 2022) explored combining 4D-Var-based DA methods with DL to predict complex high-dimensional dynamic systems. The integration of DA methods into ocean data modeling addresses key challenges such as observations sparsity and noise. DA (Carrassi et al., 2018) can reduce uncertainty and improve prediction accuracy by combining observations with model simulations. DA provides more optimized initial conditions by adding new observations at regular intervals, leading to more accurate and reliable predictions. Ensemble Kalman Filter (EnKF) (Evensen, 2003) is a widely used DA method that generates a set of model state samples representing the uncertainty of the initial conditions. EnKF updates this set of samples when new observations are received to accurately estimate the current system state. Compared to other variational methods, such as 4D-Var, EnKF has the advantages of being computationally efficient, easy to implement, and highly adaptable (Lorenc, 2003).
DL techniques have demonstrated significant potential in predicting ocean surface latent heat fluxes in recent years (Reichstein et al., 2019). In 2020, Chen et al. employed four machine learning techniques—artificial neural network (ANN), random forest (RF), Bayesian ridge regression, and random sample consensus regression (Chen et al., 2020). In 2023, Liang et al. addressed the bias in ocean surface latent heat flux predictions by modifying the vapor pressure calculation method (Liang et al., 2023). They integrated data from two satellite products and two reanalysis products to enhance the prediction of latent heat fluxes. Concurrently, Guo et al. introduced a convolutional neural network-long short-term memory-based integrated latent heat flux framework (Guo et al., 2024). This framework combines multiple remote sensing-derived algorithms, topographic variables, and eddy covariance observations, thereby improving the accuracy and reliability of estimating global land latent heat fluxes from satellite data. In the same year, Malik and colleagues validated and forecasted sea surface temperature and latent heat flux trends over the next 20 years using observations and a standard logistic curve model, revealing a high correlation between the observed trends and their predictions (Malik et al., 2024).
We present an ocean surface latent heat flux prediction model called TransNetDA that combines Transformer and DA technique to form a hybrid architecture. Specifically, the Transformer acts as an encoder and decoder and utilizes a multi-head attention mechanism to enable the model to focus better on key information, significantly improving its feature extraction capability and prediction accuracy. After the initial prediction is made, TransNetDA incorporates a DA technique known as EnKF. This technique reduces uncertainty and improves the accuracy of the prediction by combining observed data with model simulations.
The innovations and main contributions of this study are as follows: The TransNetDA model integrates DL and DA to address the challenges of nonlinearity and uncertainty in ocean dynamical systems. By leveraging the Transformer is ability to capture long-term dependencies, the model enhances prediction accuracy and robustness through the use of the EnKF. Additionally, the model incorporates a multi-head self-attention mechanism with convolutional operations, effectively extracting multi-scale spatial features.
The structure of this paper is arranged as follows: Section 2 introduces the region studied in this article and the processing of data; Section 3 provides a detailed description of the proposed TransNetDA new method for predicting ocean surface latent heat flux; Section 4 applies this method to the study area and obtains corresponding results, which are discussed in the Section 5.
This section details the geographic location of the study area, data sources, and preprocessing methods.
The ocean area under study is located on the west coast of the Pacific Ocean, which ranges from 0°−25°N and 105°−124°E. As shown in Fig. 1, this map is a simulated ocean depth distribution map to demonstrate the environmental conditions of the studied region, which includes the South China Sea, which is subject to multiple influences from island distribution, underwater topography, monsoon systems, and ocean currents, resulting in complex and variable seawater temperature conditions (Tang et al., 2022). Compared with the neighboring Pacific region, the seawater properties in this region are significantly different, which has important implications for the study of the global climate system, climate change projections, and weather patterns.
This study mainly predicts latent heat fluxes using ocean surface observations. Data from the National Oceanic and Atmospheric Administration (NOAA). Relevant data are available on the ocean-heat-fluxes website. The ocean surface heat flux climate data used are latent and sensible heat fluxes calculated from parameters such as surface atmospheric properties and sea surface temperatures by the neural network simulator of the TOGA-COARE algorithm (Wang et al., 1996). The data span from January 1988 to August 2021 and cover the global ice-free sea with a resolution of 0.25° grid every 3 hours (Madani et al., 2020).
During data preprocessing, we use grid alignment and interpolation to ensure consistency across the dataset. The raw data were stored on a daily basis, and the processed data were recorded every 3 hours from 01:30 to 22:30 with a grid accuracy of 0.25°. Furthermore, to ensure the homogeneity of the spatial data and to improve the accuracy and reliability of the analysis, we used a bilinear interpolation method to align all the spatial data points to a uniform 0.25° × 0.25° grid. The temporal and spatial resolution before and after data processing remained unchanged, which could effectively minimize the time gaps that might occur due to missing data points or irregular recording intervals, thus maintaining the continuity of the time series. In addition, a normalization process was performed to deal with the magnitude differences between different input features:
| $$ {X}_{i}=\frac{{x}_{i}-\mu }{\sigma }, $$ | (1) |
where
Finally, the training dataset consists of 58 424 samples from 2000 to 2019, 2 928 samples from 2020 for validation, and approximately 1 944 samples from 2021 for the testing phase. They are labeled as values of accurate ocean surface latent heat fluxes. Each sample consists of 100 rows and 80 columns for 8 000 data points.
We introduce TransNetDA, a novel deep learning approach integrating Transformer and EnKF, designed for efficient and precise processing of ocean surface latent heat flux data. The model utilizes an encoder-decoder framework for feature extraction, spatial transformation, and feature reconstruction through the Transformer module (Fig. 2). As shown in Fig. 2, the TransNet framework provides initial predicted values as background values for the DA phase, which are subsequently assimilated with the current time observations using EnKF. The analysis value
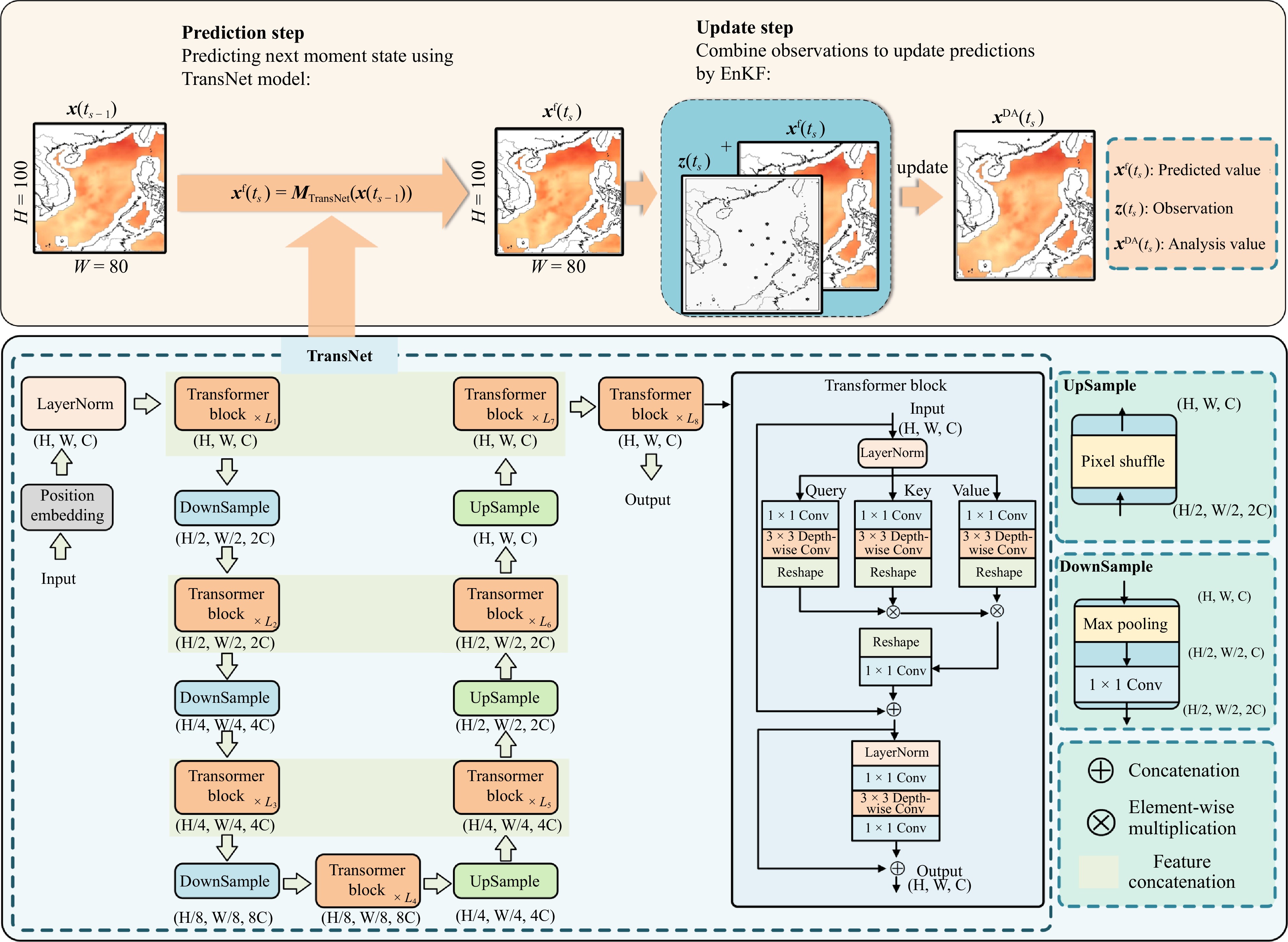
Since the attentional mechanism itself cannot discern the order of the sequence, we first encode the explicit positional information of these signal fragments to enhance their sequential information. In our model, we generate unique encodings for each position in the sequence based on sine and cosine functions at different frequencies. The position encoding is created using the following equations:
| $$ {PE}_{\left(\mathrm{pos},2i\right)}=\mathrm{sin}\left(\frac{\mathrm{pos}}{{10000}^{\frac{2i}{{d}_{\mathrm{model}}}}}\right), $$ | (2) |
| $$ {PE}_{\left(\mathrm{pos},2i+1\right)}=\mathrm{cos}\left(\frac{\mathrm{pos}}{{10000}^{\frac{2i}{{d}_{\mathrm{model}}}}}\right). $$ | (3) |
In these formulas,
For the ocean surface latent heat flux data input
As shown in Table 1, the input features
| Module | Setting | Size |
| Datasets | Input dimension | (100, 80, 1) |
| Output dimension | (100, 80, 1) | |
| Training/Validation/Test Split | 2000~2019/ 2020/2021 | |
| Encoder | Number of Layer | 4 |
| Number of Transformer Blocks | [2,3,4,4] | |
| Embedding Dimensions | [32,64,128,256] | |
| Norm layer | LayerNorm | |
| Decoder | Number of Layer | 4 |
| Number of Transformer Blocks | [2,3,4,4] | |
| Embedding Dimensions | [32,64,128,256] |
 DownLoad:
CSV
DownLoad:
CSV
The Transformer model has been widely used since it was proposed, initially for natural language processing tasks such as machine translation (Jurisic et al., 2018). Its architecture is based on the attention mechanism, which differs from traditional recurrent neural networks and convolutional neural networks (Usama et al., 2020). The Transformer model has achieved success due to its efficient parallel computing capability, powerful representation learning, and adaptability to long-distance dependencies. It has been widely applied to various NLP tasks such as text generation, text classification, and question answering systems, and has also gained great success in the field of pre-trained language models. In this study, we combined convolution operations with Transformer blocks to process two-dimensional data. By incorporating convolutional operations into the multi-head self-attention mechanism of the transformer block, we have designed a transformer block for predicting latent heat fluxes at the ocean surface. The encoder and decoder of the model consist of multiple Transformer block layers.
When designing the Transformer block, we introduced convolution operations to achieve spatial information interaction. Specifically, we chose to compute attention along the channel dimension instead of the traditional spatial dimension, ensuring consistency in calculations across any spatial range. This approach better captures and processes the complex spatial information within large sea areas, thereby completing ocean prediction tasks more accurately (Niu et al., 2021).
As shown in the TransNet structure in Fig. 2, for the input features
Since the Transformer module does not compute attention along the spatial dimension, its ability to capture spatial features is weakened. Therefore, convolution operations are needed in the feed-forward network to further enhance spatial information interaction. We use a
DA optimizes model state estimation by integrating observations and model predictions. It is a crucial technology in many geoscience fields, and plays an essential role in weather forecasting and ocean sciences in particular (Reichle, 2008). DA improves the accuracy and reliability of model predictions by using real-time or historical observations to further improve model predictions, thus ensuring that model outputs are closer to true values (Bouttier and Courtier, 2002).
EnKF as a DA technique is widely used due to its unique advantages (Cheng et al., 2023). In the context of our study, EnKF is integrated into the TransNetDA framework to ensure the accuracy and reliability of ocean surface latent heat flux predictions. EnKF applies Monte Carlo techniques to Bayesian update problems (Tierney and Mira, 1999), using a set of stochastic realizations to approximate the state of dynamic systems effectively. The state matrix of the ensemble comprises all individual state vectors:
| $$ \mathcal{X}\left(t\right)={\left[{\mathcal{X}}_{1}\left(t\right),\dots ,{\mathcal{X}}_{k}\left(t\right),\dots ,{\mathcal{X}}_{{N}_{\mathcal{e}}}\left(t\right)\right]}^{\mathrm{T}}\in {\mathbb{R}}^{{N}_{x}\times {N}_{e}}, $$ | (4) |
where
EnKF operates through two major phases: prediction and updating (Cheng et al., 2023). During prediction, the prediction of each ensemble member is independently calculated using the following model:
| $$ {\mathcal{X}}_{k}^{\mathrm{f}}\left({t}_{s}\right)={\mathcal{M}}_{\mathrm{T}\mathrm{r}\mathrm{a}\mathrm{n}\mathrm{s}\mathrm{N}\mathrm{e}\mathrm{t}}\left({\mathcal{X}}_{k}\left({t}_{s-1}\right)\right), $$ | (5) |
where
The average of all forecasts provides the ensemble mean at time
| $$ {\overline{\mathcal{X}}}^{\mathrm{f}}\left({t}_{s}\right)=\frac{1}{{N}_{e}}\sum _{k=1}^{{N}_{e}}{\mathcal{X}}_{k}^{\mathrm{f}}\left({t}_{s}\right). $$ | (6) |
Covariance of the prediction error,
| $$ {\mathit{P}}^{\mathrm{f}}\left({t}_{s}\right)=\frac{1}{{N}_{e}-1}\sum _{k=1}^{{N}_{e}} \left({\mathcal{X}}_{k}^{\mathrm{f}}\left({t}_{s}\right)-{\overline{\mathcal{X}}}^{\mathrm{f}}\left({t}_{s}\right)\right){\left({\mathcal{X}}_{k}^{\mathrm{f}}\left({t}_{s}\right)-{\overline{\mathcal{X}}}^{\mathrm{f}}\left({t}_{s}\right)\right)}^{\mathrm{T}}. $$ | (7) |
| $$ {\mathcal{X}}_{k}^{\mathrm{D}\mathrm{A}}\left({t}_{s}\right) = {\mathcal{X}}_{k}^{\mathrm{f}}\left({t}_{s}\right) + \mathit{K}\left({t}_{s}\right) \left[\mathcal{Z}\left({t}_{s}\right) - \mathcal{H}\left({\mathcal{X}}_{k}^{\mathrm{f}}\left({t}_{s}\right)\right)\right], $$ | (8) |
the Kalman gain
| $$ \mathit{K}\left({t}_{s}\right)={\mathit{P}}^{\mathrm{f}}\left({t}_{s}\right){\mathcal{H}}^{\mathrm{T}}{\left[\mathcal{H}\left({\mathit{P}}^{\mathrm{f}}\left({t}_{s}\right)\right){\mathcal{H}}^{\mathrm{T}}+\mathcal{R}\left({t}_{s}\right)\right]}^{-1}, $$ | (9) |
and the analysis ensemble is averaged to produce the final analysis values, which is the final predicted value at time
| $$ {\overline{\mathcal{X}}}^{\mathrm{D}\mathrm{A}}\left({t}_{s}\right)=\frac{1}{{N}_{e}}\sum _{k=1}^{{N}_{e}}{\mathcal{X}}_{k}^{\mathrm{D}\mathrm{A}}\left({t}_{s}\right), $$ | (10) |
where
| $$ {\mathit{P}}^{\mathrm{D}\mathrm{A}}\left({t}_{s}\right)=\left(\mathit{I}-\mathit{K}\left({t}_{s}\right)\mathcal{H}\right){\mathit{P}}^{\mathrm{f}}\left({t}_{s}\right). $$ | (11) |
In our implementation, the real-time observations of ocean surface latent heat flux are continuously fed into the model. EnKF adjusts the model states by minimizing the difference between the predicted and observed values, thus correcting the predictions in real time. This process not only enhances the predictive accuracy of the model but also improves its robustness against uncertainties in the data.
By combining the strengths of the Transformer architecture for feature extraction and EnKF for real-time DA, TransNetDA provides a powerful tool for precise and efficient ocean surface latent heat flux prediction. The prediction of the TransNetDA model includes two phases, which are the initial prediction of TransNet and the prediction after assimilation using observations, where the assimilation step involves the DA between the predictions of the TransNet model and the real-time observations. The TransNet model is responsible for providing the initial predictions based on the historical data, which serve as the background values to be used in the DA phase, and subsequently by integrating the observations to further obtain analysis values, whose values are used as predictions for DA, which are the final predictions of the TransNetDA model. For the convenience of presenting the results, the predicted values of TransNetDA shown below refer to the final predicted values after performing the ensemble averaging process.
Two key metrics are used in this study to assess model performance: root mean square error (RMSE) and coefficient of determination (
| $$ \mathrm{R}\mathrm{M}\mathrm{S}\mathrm{E}\left(y,\widehat{y}\right)=\sqrt{\frac{1}{m}\sum _{i=1}^{m}{\left({y}_{i}-{\widehat{y}}_{i}\right)}^{2}}, $$ | (12) |
where
| $$ {\mathrm{R}}^{2}\left(y,\widehat{y}\right)=1-\frac{\displaystyle\sum _{i=1}^{m}{\left({y}_{i}-{\widehat{y}}_{i}\right)}^{2}}{\displaystyle\sum _{i=1}^{m}{\left({y}_{i}-\bar{y}\right)}^{2}}, $$ | (13) |
where
Combining RMSE and
Changes in ocean surface latent heat flux influence ocean surface temperatures, thereby affecting global ocean circulation and climate patterns (Large and Yeager, 2012). Therefore, developing efficient prediction tools holds significant scientific value and potential for meteorological and oceanographic research applications. The Transformer has powerful feature extraction capabilities, allowing it to extract high-level and complex features from multidimensional data, and it excels in predicting ocean surface latent heat flux. EnKF can enhance the performance of the Transformer model in ocean data prediction. By assimilating observations into model predictions and continuously updating the model states, the predictions of the Transformer become closer to actual observations. Specifically, we perform DA every 6 hours using random noise generated from a normal distribution
In this section, we compare the performance of TransNetDA with ConvLSTM, LSTM, and U-Net to predict hourly ocean surface latent heat flux and compare it with accurate data. The performance of these models is evaluated by predicting the periods of ocean surface latent heat flux. These models predict the change in ocean surface latent heat flux values over the next 24 hours by learning from historical data, starting at 01:30 and getting a prediction every 3 hours. Additionally, we compare with two baseline models such as persistence (Kessler et al., 2016) and climatology (historical day-of-year mean and variance) models (Ward et al., 2014). The persistence approach, which predicts future values based on current or past values, can be used to predict the dynamics of high inertia systems, which are common in lakes and reservoirs. The Climatology model, based on historical observations, uses long-term averages at the same time of year to predict future conditions. This method performs better in long-term predictions, especially when the dynamics are dominated by repetitive seasonal cycles (Olsson et al., 2024). The performance of these models is evaluated using RMSE and
As shown in Table 2, TransNetDA performs excellently predicting ocean surface latent heat flux. At 01:30, the RMSE of TransNetDA is 2.385, increasing to 7.227 at 04:30 and decreasing to 4.785 at 07:30. Additionally, the
| Model | 01:30 | 04:30 | 07:30 | |||||
| $ {\mathrm{R}}^{2} $ | RMSE | $ {\mathrm{R}}^{2} $ | RMSE | $ {\mathrm{R}}^{2} $ | RMSE | |||
| Persistence | 0.899 | 18.716 | 0.956 | 9.993 | 0.962 | 8.739 | ||
| Climatology | 0.471 | 42.851 | 0.406 | 41.935 | 0.339 | 43.109 | ||
| U-Net | 0.973 | 6.945 | 0.907 | 11.875 | 0.859 | 14.215 | ||
| LSTM | 0.929 | 10.354 | 0.863 | 13.801 | 0.786 | 17.633 | ||
| ConvLSTM | 0.955 | 8.283 | 0.894 | 12.315 | 0.835 | 15.504 | ||
| TransNetDA | 0.997 | 2.385 | 0.970 | 7.227 | 0.985 | 4.785 | ||
DownLoad:
CSV
In contrast, the RMSE of U-Net is 6.945 at 01:30, 11.875 at 04:30, and 14.215 at 07:30. The
For Persistence, the RMSE is 18.716 at 01:30, decreasing to 9.993 at 04:30, and further to 8.739 at 07:30. The
The comparison of RMSE and
TransNetDA, due to its multi-scale attention mechanism, enables the model to focus on critical regions at different scales. This mechanism enhances the ability of the model to capture complex spatial patterns and ocean surface latent heat flux dynamics, resulting in more accurate predictions. In contrast, although U-Net has strong feature extraction capabilities, it needs the design to specifically emphasize multi-scale features, limiting its performance in handling complex meteorological data. Although ConvLSTM and LSTM perform well in processing time series data, they need help to capture and integrate multi-scale spatial features. ConvLSTM improves upon LSTM by incorporating spatial information, but both models face challenges when handling very long data sequences, potentially encountering gradient-related issues that affect prediction accuracy. Persistence, while simple and often effective for short-term predictions, shows significant limitations as it relies solely on the latest observations, leading to larger errors over longer periods (Gong and Wang, 1998). Climatology can predict future climate states by averaging historical data (Liu et al., 2023), but its reliance on long-term averages does not capture short-term changes or anomalies in climate. EnKF continuously corrects model predictions, reducing cumulative errors in long-term forecasts and ensuring the stability and accuracy of the Transformer model in long-term predictions. During the model training process, EnKF can integrate real-time observations, which improves the learning ability and prediction performance of the model (Chen et al., 2011).
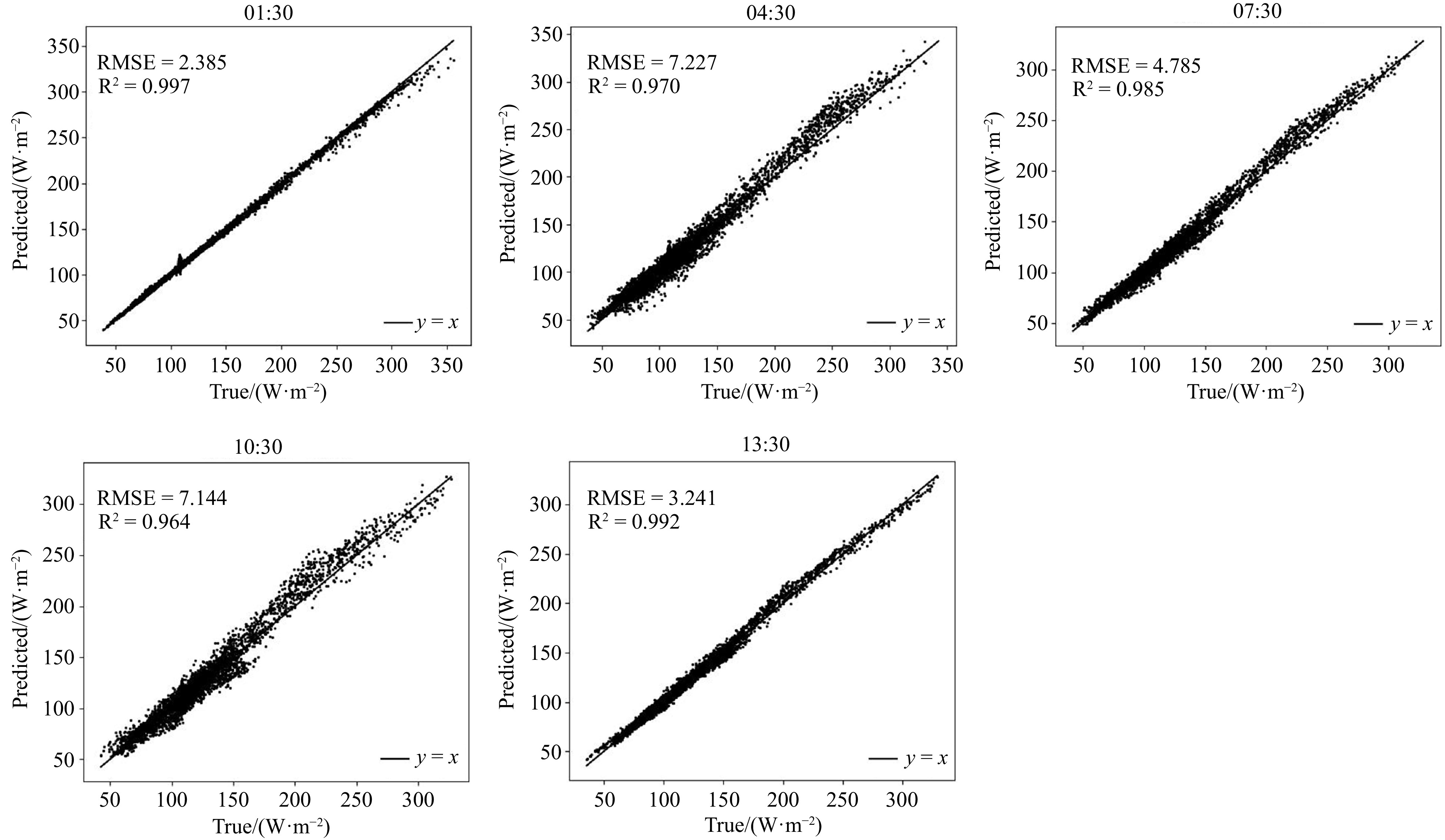
In this section, to further demonstrate the predictive performance of the TransNetDA model, we compare the predicted and true values of ocean surface latent heat fluxes at different times in different months. We use scatterplots to evaluate these comparisons. In particular, we present results for all days at different time points in January, March, May, and July, where the number of points per subplot for each month is 248 000 (8 000 points per day per hour).
Figure 3 shows the predicted values of the TransNetDA model against the true values at multiple time points in January. The


The scatterplots for May show a range of
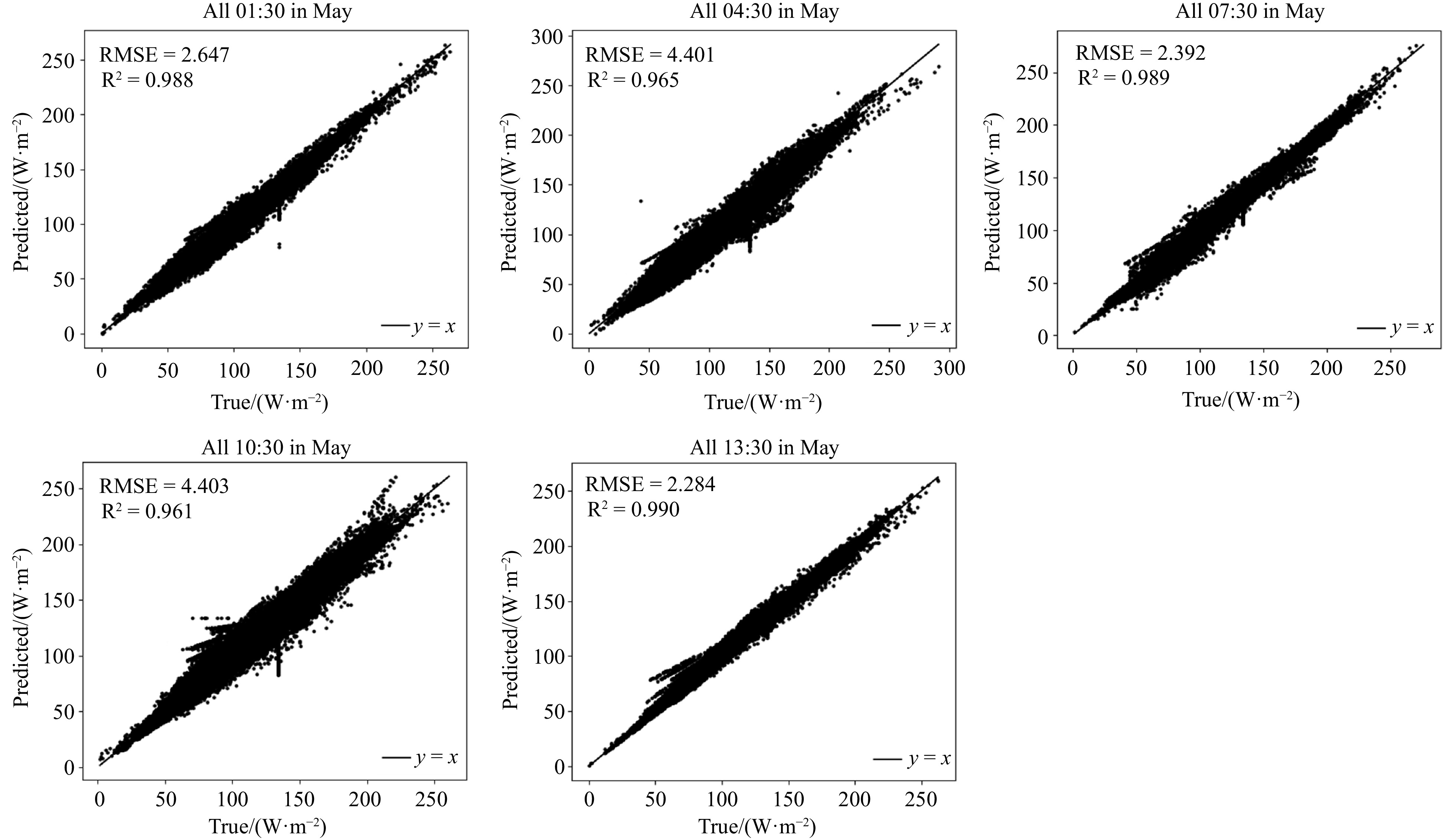

The significant improvement in prediction accuracy at 07:30 and 13:30 compared to the previous times (01:30, 04:30, and 10:30) can be attributed to the integration of DA techniques. DA enhances model predictions by incorporating observations and improving the initial conditions. At 07:30 and 13:30, the increased availability and incorporation of observed data allowed the TransNetDA model to more effectively correct discrepancies between model predictions and observed data. This resulted in higher
In this section, we present the validation results of the TransNet model. In our model training process, 58 424 samples are used for training and 2 928 samples are used for validation. The labels used to train the TransNet model are the ocean surface latent heat flux data values per three hours in the ocean surface latent heat flux dataset. The network structure parameters of the TransNet model are listed in Table 1. The training and prediction are performed on a server with an NVIDIA Tesla A100 GPU, 128 GB of RAM, and 2 TB of storage. The operating system used is Ubuntu 20.04, with the main tools and libraries including Python 3.8 and TensorFlow 2.4.
The training and validation loss and accuracy curves for the TransNet model are shown in Fig. 7. The subplot on the left displays the loss curves, where both the training and validation losses continue to decrease as the number of training rounds increases. Around round 100, the validation loss shows a significant decrease and aligns closely with the training loss, indicating that the model generalizes well and is not overfitting. By round 200, both curves begin to level off, suggesting that the model has reached a steady state. The final training and validation loss values are close and fluctuate less, confirming the robustness of the model.
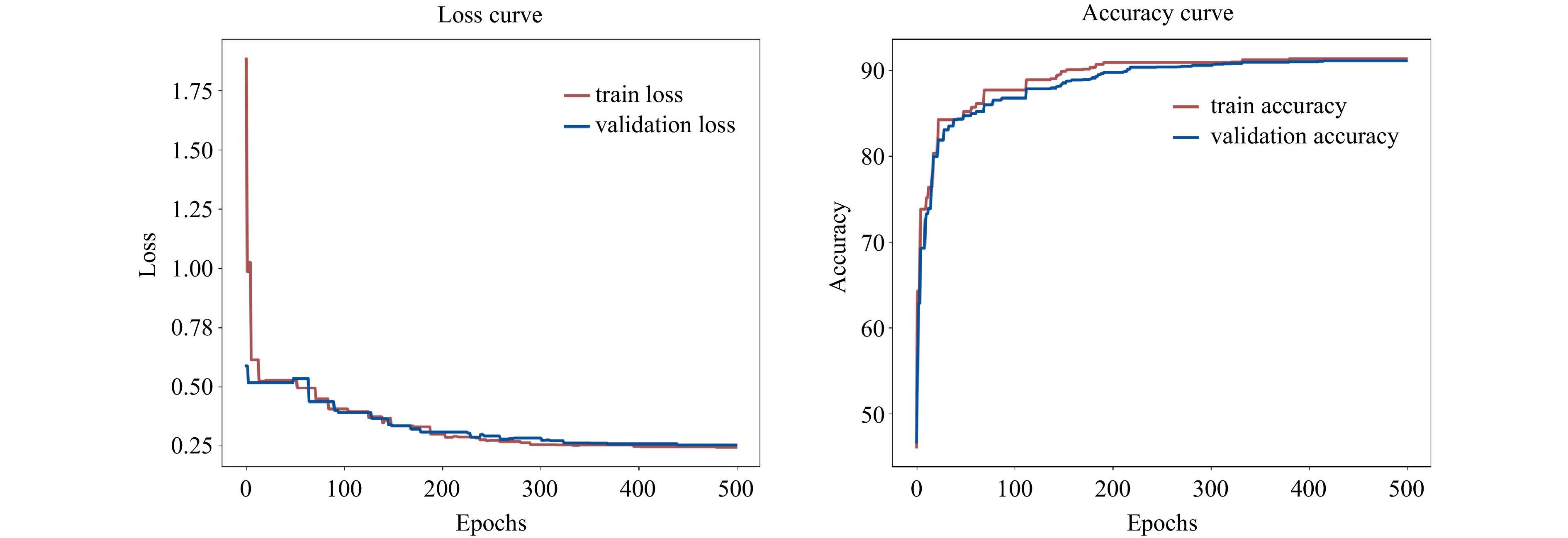
The right subplot shows the accuracy curves for training and validation. As the number of training rounds increases, the model reaches about 80% accuracy by round 50, and the rate of improvement begins to slow down. This indicates that the model is effectively capturing the underlying patterns of the data. Between rounds 50 and 100, the accuracy continues to steadily improve, reaching approximately 90%. After this point, the accuracy curve begins to flatten, suggesting that the model is approaching its maximum performance. From round 200 onwards, the training and validation accuracy curves converge and stabilize at approximately 92%. The tight alignment of these curves throughout the training process indicates that the performance of the model on the training and validation datasets remains consistent without significant overfitting.
In summary, the training process visualized by the loss and accuracy curves shows that the TransNet model maintains good generalization performance on the validation data while learning effectively from the training data. The convergence of the loss and accuracy curves indicates that the model achieves a high level of performance while minimizing the risk of overfitting.
We conduct ablation experiments in order to assess the impact of DA using EnKF in the TransNet model. The experiment aims to understand the importance of DA and its contribution to improving the performance of ocean surface latent heat flux prediction. By comparing and analyzing the performance of TransNetDA (Fig. 8) and TransNet (Fig. 10), we found that there is a significant difference in prediction accuracy between the two models. Compared to the standard TransNet model, TransNetDA, which incorporates EnKF for DA, outperforms the standard TransNet model in terms of metrics and frequency of DA. The results show that TransNetDA has lower RMSE values and higher
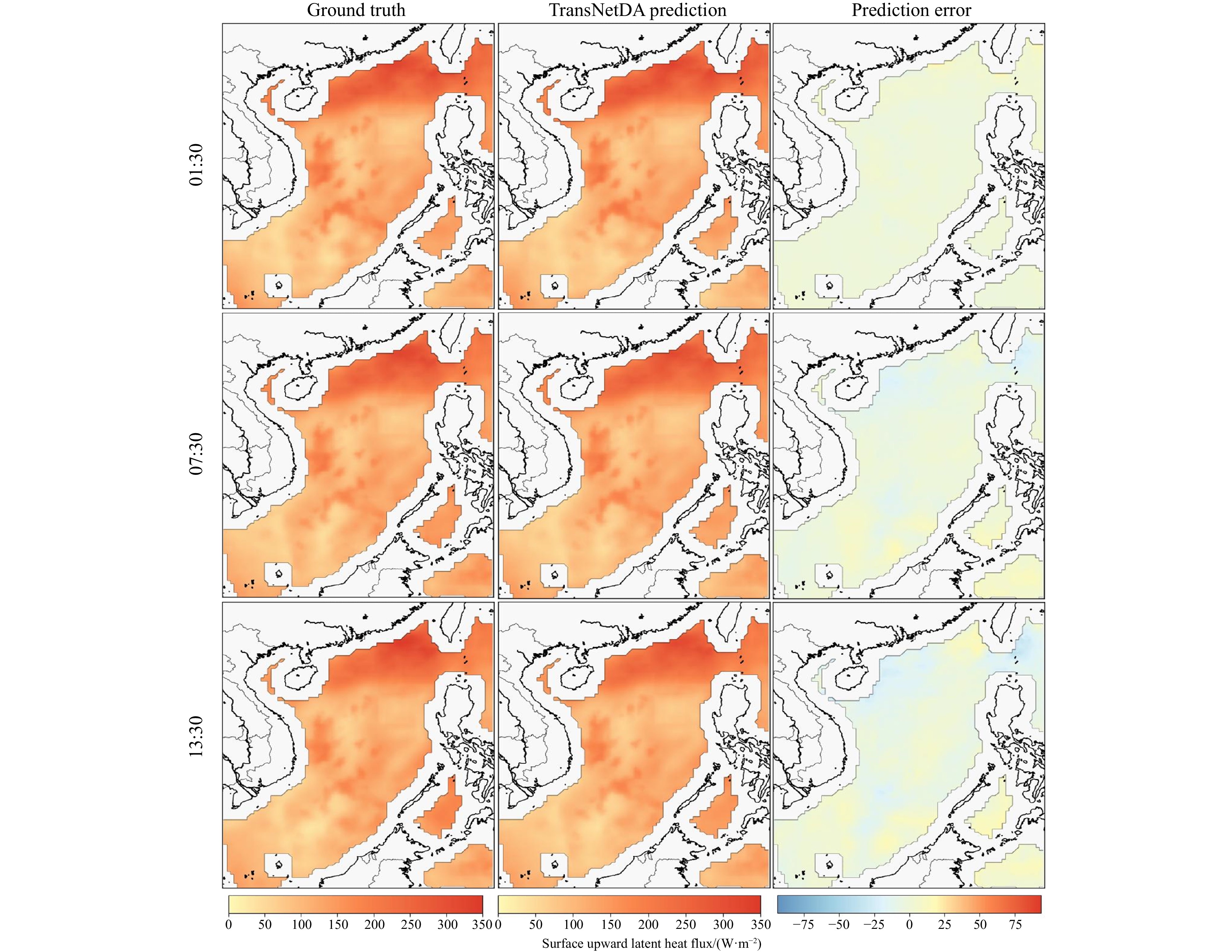

In summary, the integration of EnKF into the TransNet framework to form TransNetDA demonstrates the key role of DA in improving model performance. Higher accuracy and stability achieved through EnKF. Ablation experiments confirmed frequent DA is essential to maintain high prediction accuracy and effectively manage uncertainty in marine data. Throughout the study period, the RMSE of the method remained below 10 W/m², and the
To systematically analyze the impact of DA frequency on operational prediction performance, this study explores the effects of different assimilation frequencies to determine the optimal frequency for use in actual observations (Durand and Margulis, 2006). Specifically, we evaluated three DA frequencies: every 6 hours, 12 hours, and 24 hours (Fig. 11).
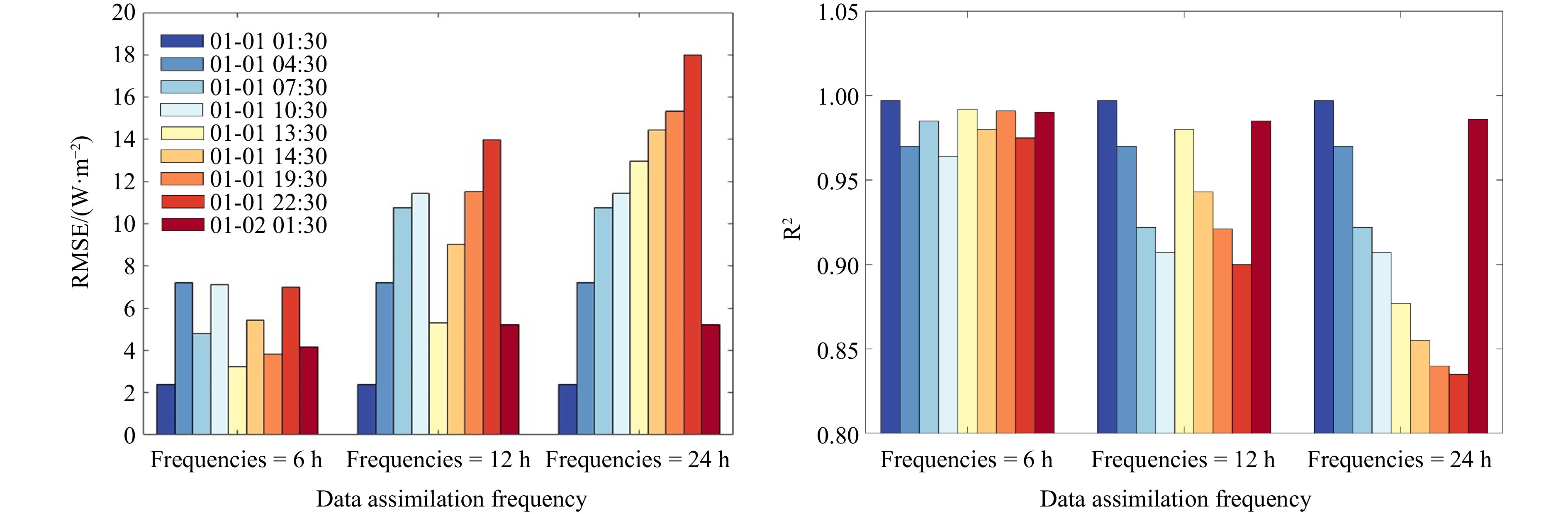
By selecting these frequencies, we systematically assessed the specific impact of different DA strategies on prediction accuracy (Geer et al., 2018). The evaluation focused on calculating the RMSE and
The results indicate that shortening the DA cycle can improve prediction accuracy (Ruiz et al., 2013). The critical role of DA frequency in enhancing the prediction performance of ocean surface latent heat flux has been confirmed. Frequent DA can reduce prediction errors, enhance the correlation between the model and actual meteorological data, and improve the reliability and utility of the predictions (Liu et al., 2012; Yucel et al., 2015). The TransNetDA method performs excellently in predicting ocean surface latent heat flux, especially when the DA frequency is set to every 6 (Fig. 8) and 12 hours. As shown in Fig. 11, these data regions further validate the high performance of the combination of TransNet and EnKF in DA, significantly enhancing the accuracy and stability of ocean surface latent heat flux prediction.
DA is crucial for improving the accuracy and reliability of model predictions. By incorporating real-time observations, EnKF helps correct prediction trajectories, reduce errors, and enhance the correlation between model predictions and actual observations (Liu et al., 2016). This continuous correction ensures that the model remains consistent with the ever-changing ocean environment. The results of the ablation experiments show that frequent DA (every 6 hours) resulted in the highest prediction accuracy, with TransNetDA maintaining low RMSE values and high
This study presents TransNetDA, which combines the Transformer architecture and the EnKF to accurately predict ocean surface latent heat fluxes. By comparing with a variety of baseline models, including Persistence, Climatology, U-Net, LSTM and ConvLSTM, the TransNetDA model is highly effective in terms of prediction accuracy and reliability. Firstly, the Transformer component in TransNetDA excels in feature extraction, capturing complex spatio-temporal dependencies in the data using its multi-head self-attention mechanism. Secondly, EnKF plays a key role in assimilating real-time observations and continuously updating model predictions to reduce errors and improve accuracy. This combination ensures that TransNetDA maintains high prediction accuracy over a long period.
The results of this study emphasize the effectiveness of frequent DA. By integrating observations every six hours, TransNetDA achieves optimal performance, characterized by the lowest RMSE values and the highest
Future research tasks involve combining TransNetDA with advanced deep learning methods, such as graph neural networks and generative adversarial networks, to enhance its ability to model complex non-linear relationships in the data. This integration aims to improve prediction accuracy and expand the applicability of the model in operational forecasting. It will also refine the accuracy and reliability of ocean surface latent heat flux predictions under sparse observations conditions, thereby providing timely and accurate forecasts for various oceanographic and environmental decision-making processes.
Acknowledgement: Authors gratefully thank the respected reviewers for their deep and careful work for this paper.The authors declare no competing interests.

Supported by:
Beijing Renhe Information Technology Co. Ltd

Yahui Liu, Hengxiao Li, Jichao Wang. A deep learning model for ocean surface latent heat flux based on Transformer and data assimilation[J]. Acta Oceanologica Sinica. doi: 10.1007/s13131-024-2392-x

| Module | Setting | Size |
| Datasets | Input dimension | (100, 80, 1) |
| Output dimension | (100, 80, 1) | |
| Training/Validation/Test Split | 2000~2019/ 2020/2021 | |
| Encoder | Number of Layer | 4 |
| Number of Transformer Blocks | [2,3,4,4] | |
| Embedding Dimensions | [32,64,128,256] | |
| Norm layer | LayerNorm | |
| Decoder | Number of Layer | 4 |
| Number of Transformer Blocks | [2,3,4,4] | |
| Embedding Dimensions | [32,64,128,256] |
DownLoad:
CSV
| Model | 01:30 | 04:30 | 07:30 | |||||
| $ {\mathrm{R}}^{2} $ | RMSE | $ {\mathrm{R}}^{2} $ | RMSE | $ {\mathrm{R}}^{2} $ | RMSE | |||
| Persistence | 0.899 | 18.716 | 0.956 | 9.993 | 0.962 | 8.739 | ||
| Climatology | 0.471 | 42.851 | 0.406 | 41.935 | 0.339 | 43.109 | ||
| U-Net | 0.973 | 6.945 | 0.907 | 11.875 | 0.859 | 14.215 | ||
| LSTM | 0.929 | 10.354 | 0.863 | 13.801 | 0.786 | 17.633 | ||
| ConvLSTM | 0.955 | 8.283 | 0.894 | 12.315 | 0.835 | 15.504 | ||
| TransNetDA | 0.997 | 2.385 | 0.970 | 7.227 | 0.985 | 4.785 | ||
DownLoad:
CSV
| Module | Setting | Size |
| Datasets | Input dimension | (100, 80, 1) |
| Output dimension | (100, 80, 1) | |
| Training/Validation/Test Split | 2000~2019/ 2020/2021 | |
| Encoder | Number of Layer | 4 |
| Number of Transformer Blocks | [2,3,4,4] | |
| Embedding Dimensions | [32,64,128,256] | |
| Norm layer | LayerNorm | |
| Decoder | Number of Layer | 4 |
| Number of Transformer Blocks | [2,3,4,4] | |
| Embedding Dimensions | [32,64,128,256] |
| Model | 01:30 | 04:30 | 07:30 | |||||
| $ {\mathrm{R}}^{2} $ | RMSE | $ {\mathrm{R}}^{2} $ | RMSE | $ {\mathrm{R}}^{2} $ | RMSE | |||
| Persistence | 0.899 | 18.716 | 0.956 | 9.993 | 0.962 | 8.739 | ||
| Climatology | 0.471 | 42.851 | 0.406 | 41.935 | 0.339 | 43.109 | ||
| U-Net | 0.973 | 6.945 | 0.907 | 11.875 | 0.859 | 14.215 | ||
| LSTM | 0.929 | 10.354 | 0.863 | 13.801 | 0.786 | 17.633 | ||
| ConvLSTM | 0.955 | 8.283 | 0.894 | 12.315 | 0.835 | 15.504 | ||
| TransNetDA | 0.997 | 2.385 | 0.970 | 7.227 | 0.985 | 4.785 | ||
 DownLoad:
DownLoad: